1.
Die Idee der Self-Sovereign Identity ^
2.1.
Blockchain ^
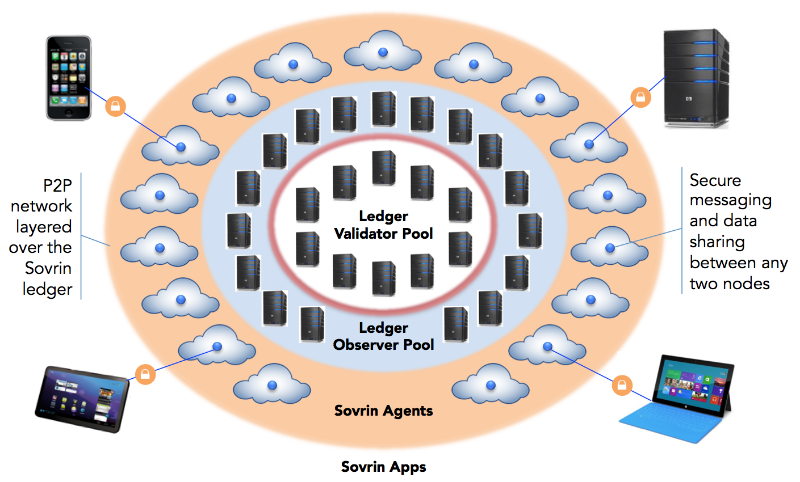
Abbildung 1: Übersicht Sovrin-Network4
Daher geht der Trend derzeit eher dahin, sogenannte Metadaten in die Blockchain zu integrieren, etwa durch Decentralized Identifiers (DIDs) und zugehörige DID-Dokumente.
2.2.
DID und DID-Dokument ^
did:sov:21tDAKCERh95uGgKbJNHYp
{
"@context": "https://w3id.org/did/v1",
"id": "did:sov:21tDAKCERh95uGgKbJNHYp",
"keys": [{
"id": "#key1",
"type": "rsa-2017-pem",
"value": "-----BEGIN KEY...END KEY-----\r\n"
}],
"services": [{
"id": "#srv1",
"type": "agent",
"name": "agent",
"keyref": "#key1",
"endpoint": "https://agent.example.com/"
}]
}
2.3.
Agents und Verifiable Claims ^
2.4.
Zero-Knowledge-Proof und Korrelierbarkeit ^
3.1.
Datenschutz ^
Hinzu kommt, dass der Nutzung von Rainbow-Tables auch bei unsicheren Hash-Funktionen durch die Verwendung eines sogenannten Salts24 entgegengewirkt werden kann. Dabei werden, vor der Anwendung der (öffentlich zugänglichen) Hash-Funktion auf die betreffenden Daten, diese Daten noch mit einer (geheimen) Funktion – dem Salt – verändert, wodurch sich auch die errechneten Hash-Werte grundlegend ändern und ein Rainbow-Table ohne Kenntnis des Salt25 nicht erstellt werden kann. Die Kenntnis des Salt könnte dazu führen, dass der Verantwortliche personenbezogene Daten verarbeitet. In jedem Fall, ist die Speicherung von, wenn auch kryptographisch verschlüsselten, Daten in einem public ledger aufgrund dessen Unabänderlichkeit problematisch, da sich die Rückführbarkeit mitunter in naher Zukunft, durch neue Technologien ergeben kann, die Daten jedoch bereits distributed sind.
Verarbeitung i.S.d. Art. 4 Z 1 DSGVO ist jeder mit oder ohne Hilfe automatisierter Verfahren ausgeführte Vorgang oder jede solche Vorgangsreihe im Zusammenhang mit personenbezogenen Daten wie etwa das Erheben, das Erfassen, das Speichern, das Auslesen, das Abfragen von Daten etc. Verantwortlicher i.S.d. Art. 4 Z 7 DSGVO ist jene natürliche oder juristische Person, Behörde, Einrichtung oder andere Stelle, die allein oder gemeinsam über die Zwecke und Mittel der Verarbeitung von personenbezogenen Daten entscheidet.
3.2.
eIDAS Verordnung und E-GovG ^
4.
Fazit ^
- Kontrolle der Nutzer über ihre Daten
- Sicherheit und Integrität der Daten
- Portabilität der Daten und Souveränität (in dem Sinne, dass dem Nutzer die Kontrolle über seine Daten nicht genommen werden kann)
- 1 Abraham, Whitepaper Self-Sovereign Identity (https://www.egiz.gv.at/files/download/Self-Sovereign-Identity-Whitepaper.pdf [alle Websites zuletzt abgerufen am 3. Januar 2018]).
- 2 Sovrin (https://sovrin.org).
- 3 Sovrin Trust Framework (https://sovrin.org/library/trust-framework/).
- 4 How Sovrin Works (https://sovrin.org/library/how-sovrin-works/).
- 5 DID (Decentralized Identifier) Data Model and Generic Syntax 1.0 Implementer’s Draft 01 (https://github.com/WebOfTrustInfo/rebooting-the-web-of-trust-fall2016/blob/master/draft-documents/did-implementer-draft-10.md).
- 6 Sovrin Provisional Trust Framework (https://sovrin.org/wp-content/uploads/2017/07/Sovrin-Provisional-Trust-Framework-2017-06-28.pdf).
- 7 Sporny/Longley, Verifiable Claims Data Model and Representations (Work in Progress!) (https://www.w3.org/TR/verifiable-claims-data-model/).
- 8 Sovrin Provisional Trust Framework (https://sovrin.org/wp-content/uploads/2017/07/Sovrin-Provisional-Trust-Framework-2017-06-28.pdf).
- 9 Abraham (Fn. 1).
- 10 Verordnung (EU) 2016/679 des Europäischen Parlaments und des Rates vom 27. April 2016 zum Schutz natürlicher Personen bei der Verarbeitung personenbezogener Daten, zum freien Datenverkehr und zur Aufhebung der Richtlinie 95/46/EG (Datenschutzgrundverordnung; kurz: DSGVO).
- 11 Hötzendorfer, Datenschutz und Privacy by Design im Identitätsmanagement (2016), 126.
- 12 Ernst in: Paal/Pauly (Hrsg.), Datenschutz-Grundverordnung1 (2017) Art. 4 Rz 9.
- 13 Für eine Darstellung des Meinungsstreites unter Einbeziehung der österreichischen Literatur siehe Hötzendorfer (Fn. 11), 132.
- 14 EuGH 19. Oktober 2016, Rs C-582/14, Breyer/Deutschland.
- 15 Hötzendorfer (Fn. 11), 137.
- 16 EuGH 19. Oktober 2016, Rs C-582/14, Breyer/Deutschland, Rz 45–48.
- 17 Daten juristischer Personen sind von der ab 25. Mai 2018 in Geltung stehenden DSGVO nicht umfasst. Zu beachten ist allerdings, dass § 1 DSG 2000 auch nach Erlassung des Datenschutz-Anpassungsgesetzes 2018 weiterhin in Geltung steht; die Frage des Schutzes juristischer Personen ist sohin – zumindest in Österreich – weiterhin strittig. Gegen einen Datenschutz für juristische Personen etwa Leissler, Datenschutz für juristische Personen – ein Blick in die Zukunft, ecolex 2017, 1222.
- 18 Etwa MD-4 oder MD-5.
- 19 Lässt man allfälliges Zusatzwissen des Verantwortlichen außer Betracht.
- 20 Datenbanken, welche die Hashwerte einer Vielzahl von in Frage kommenden Eintragungen enthalten, vgl. hierzu auch Voitel, Sind Hash-Werte personenbezogene Daten?, DuD Datenschutz und Datensicherheit 11/2017, 686.
- 21 Voitel (Fn. 20), 686.
- 22 EuGH 19. Oktober 2016, Rs C-582/14, Breyer/Deutschland.
- 23 Zu MD4 und MD5 und SHA-1 siehe etwa bereits Lucks, Zur Sicherheit kryptographischer Hashfunktionen, http://www.cryptolabs.org/hash/LucksWeisSicherheitHash0305.pdf (veröffentlicht am 16. März 2005).
- 24 Also eines Initialisierungswertes, welcher den Grunddatensatz vor der Anwendung der Hash-Funktion adaptiert, wodurch auch bei Kenntnis der Hash-Funktion nicht auf den Grunddatensatz geschlossen werden kann, zum Begriff «Salt» siehe etwa http://www.aspheute.com/english/20040105.asp.
- 25 Die Kenntnis eines solchen verwendeten Salts, wäre diesfalls ein solches oben erwähntes «Zusatzwissen», welches den Personenbezug für den jeweiligen Verantwortlichen herzustellen vermag.
- 26 So etwa auch (allerdings bezogen insbesondere auf die Bitcoin-Blockchain): Schrey/Thalhofer, Rechtliche Aspekte der Blockchain, NJW 2017, 1433.
- 27 Vgl. Erwägungsgrund 40 DSGVO.
- 28 Schrey/Thalhofer (Fn. 26), 1434.
- 29 Ernst in: Paal/Pauly (Fn. 12), Art. 4 Rz 78.
- 30 Art. 7 Abs. 3 DSGVO.
- 31 Art. 9 Abs. 2 lit. e) DSGVO.
- 32 Auch wenn die Berechtigung, neue Blöcke anzuhängen, bei ausgewählten nodes liegt (permissioned).
- 33 Dohr/Pollirer/Weiss/Knyrim, DSG2 § 1 (Stand 26. November 2015, rdb.at) Rz 7.
- 34 I.S.d. Grundsatzes des Datenschutzes durch Technikgestaltung (Art. 25 DSGVO).
- 35 Die Festlegung der Mindestanforderungen an die technischen Spezifikationen erfolgt in der Durchführungsverordnung der EU-Kommission 2015/1502.
- 36 Cutler/Ho, Self-Sovereign Identity and Distributed Ledger Technology: Framing the Legal Issues (https://www.perkinscoie.com/en/news-insights/self-sovereign-identity-and-distributed-ledger-technology.html) .
- 37 Vgl. Art. 25 DSGVO.





